
Internal link (Liên kết nội bộ) là các liên kết đi từ các trang của cùng 1 tên miền đó. Internal link có tác dụng tốt nhất cho việc thiết lập cấu trúc trang web và lan truyền link juice. Vì lý do đó, bài viết này sẽ chia sẻ việc xây dựng một cấu trúc trang web với các internal link thân thiện SEO.
Internal link là gì?
Internal link (Liên kết nội bộ) là các liên kết đi từ các trang của cùng 1 tên miền đó. Chúng thường được sử dụng trong việc điều hướng chính website.
Cú pháp:
Chức năng chính của internal link
• Điều hướng website.
• Thiết lập hệ thống phân cấp thông tin trong website.
• Giúp phân tán link juice cho các trang.
Tầm quan trọng trong SEO
Liên kết nội bộ có tác dụng tốt cho việc tạo nên cấu trúc site và phân bổ link juice. Vì lý do đó, internal link có phần quan trọng với SEO.
Công cụ tìm kiếm cần phải nhìn thấy nội dung của từng trang cụ thể để liệt kê, phân loại website đó dựa trên dữ liệu và các chỉ mục keyword khổng lồ của nó. Nó cũng cần có được quyền truy cập vào cấu trúc các liên kết – cấu trúc này cho phép công cụ tìm kiếm duyệt các đường dẫn của một website – để có thể tìm được tất cả các trang. Rất nhiều website đã phạm một lỗi lầm nghiêm trọng là giấu đi các liên kết điều hướng chính khiến công cụ tìm kiếm không thể truy cập được. Điều này cản trở khả năng liệt kê trong dữ liệu của công cụ tìm kiếm. Hình dưới đây minh hoạ cho vấn đề này:
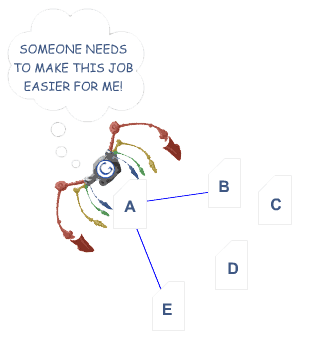
Trong ví dụ trên, bot Google đến trang "A" và nhìn thấy internal đến tới trang "B" và "E". Tuy nhiên bot Google lại không có cách nào tiếp cận hai trang quan trọng C và D cũng thuộc website. Thậm chí, Google không biết chúng tồn tại, vì không có liên kết trực tiếp hay liên kết trỏ tới hai trang này. Theo Google, các trang này về cơ bản không tồn tại – bất kể chúng nó nội dung tốt, từ khoá nhắm đúng tới mục tiêu và cách tiếp thị thông minh thì các trang đó cũng không tạo ra bất kỳ sự khác biệt nào – đơn giản vì ngay từ đầu ‘bot Google’ đã không thể tiếp cận được những trang đó.
Cấu trúc tối ưu cho website sẽ trông giống như một kim tự tháp (dấu chấm lớn phía trên là trang chủ):
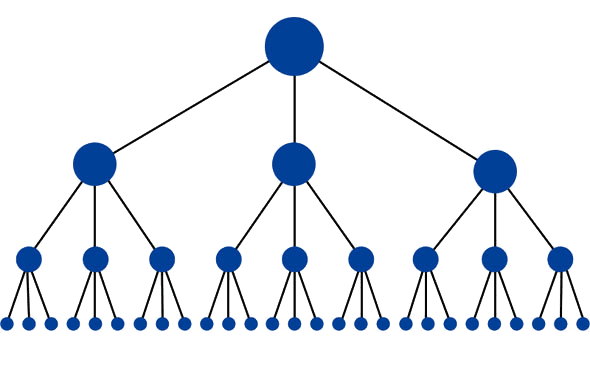
Cấu trúc này có số lượng tối thiểu các liên kết giữa trang chủ và các trang khác. Dạng này khá hữu ích vì nó cho phép link juice được liên kết thông suốt trong toàn bộ website, do đó tang tiềm năng xếp hạng cho mỗi trang. Đây là cấu trúc phổ biến tại nhiều website có chất lượng cao (như Amazon.com) qua hình thức thể loại và tiểu thể loại của hệ thống.
Nhưng làm sao để tạo ra cấu trúc này? Cách tốt nhất để làm điều này là dung các liên kết nội bộ và cấu trúc URL bổ sung. Ví dụ, tạo liên kết nội bộ đến trang https://www.chidoanh.com/dich-vu-seo/ với anchor text là "dịch vụ SEO”. Dưới đây là định dạng chuẩn cho một liên kết nội bộ. Giả sử liên kết này là trên tên miền chidoanh.com
Đây là định dạng cơ bản nhất của một liên kết và rất dễ hiểu đối với công cụ tìm kiếm. Công cụ tìm kiếm biết rằng nó cần thêm liên kết này vào đồ thị liên kết của trang web, sử dụng nó để tính toán các biến truy vấn độc lập (như MozRank ), và lần theo những liên kết này để lập chỉ mục nội dung của các trang.
Dưới đây là một số lý do phổ biến tại sao các trang không thể truy cập được, và do đó, có thể không được index.
Liên kết trong các mẫu yêu cầu thông tin
Các mẫu này có thể bao gồm các yếu tố cơ bản như một trình đơn hoặc các yếu tố phức tạp như một bản điều tra toàn diện. Trong cả hai trường hợp, công cụ tìm kiếm sẽ không cố gắng điền vào các mẫu đó, nên tất cả nội dung hay liên kết có thể được truy cập thong qua một mẫu như vậy là vô hình với công cụ tìm kiếm.
Liên kết trong Javascript không phân tích được
Liên kết được xây dựng bằng Javascript, hoặc là không thể crawl được, hoặc bị giảm giá trị tùy thuộc vào lượng xuất hiện và sử dụng. Vì lý do này, liên kết HTML tiêu chuẩn được khuyến khích sử dụng thay vì liên kết Javascript dựa trên bất kỳ trang nào coi lượng truy cập qua công cụ tìm kiếm là quan trọng.
Liên kết trong Flash, Java hoặc Plug-Ins khác
Công cụ tìm kiếm thường không thể truy cập bất kỳ liên kết nhúng trong Flash, Java applet, và các plug-in.
Liên kết chỉ tới trang bị chặn bởi các Robots Meta Tag hoặc Robots.txt
Meta Robots tag và file robots.txt đều cho SEOer hạn chế việc truy cập của bot vào bất kỷ trang nào.
Liên kết trên các trang có hàng trăm hoặc hàng ngàn liên kết
Các công cụ tìm kiếm đều có một giới hạn thu thập dữ liệu khoản 150 liên kết trong mỗi trang trước khi nó ngừng bổ sung liên kết đến từ trang gốc. Giới hạn này có phần linh hoạt, và các trang đặc biệt quan trọng có thể lên đến 200 hoặc thậm chí 250 liên kết đi theo, nhưng trong thực tế, nên hạn chế số lượng các liên kết trên bất kỳ trang nào ở con số 150
Liên kết trong Frames hoặc I-Frames
Về mặt kỹ thuật, liên kết trong cả Frames và I-Frames là có thể truy cập được bằng công cụ tìm kiếm, nhưng cả hai đều có vấn đề về tổ chức, sắp xếp và follow. Chỉ người dùng cao cấp có hiểu biết kỹ thuật tốt về cách công cụ tìm kiếm lập chỉ mục các liên kết trong frames mới nên dùng các yếu tố này, kết hợp với dùng các liên kết nội bộ.
Bằng cách tránh những lỗi trên, một webmaster có thể xây dựng một website sáng sủa với các liên kết HTML có thể truy cập được, cho phép công cụ tìm kiếm dễ dàng lập chỉ mục các trang nội dung của website. Các liên kết có thể có thuộc tính bổ sung áp dụng cho chúng, nhưng các cỗ máy tìm kiếm bỏ qua gần như tất cả trong số này, ngoại trừ thuộc tính quan trọng rel="nofollow”.
Rel="nofollow " có thể được sử dụng với cú pháp sau:
Trong ví dụ này , bằng cách thêm thuộc tính rel="nofollow " vào thẻ liên kết, webmater cho công cụ tìm kiếm biết họ không muốn liên kết này được coi như một liên kết truy cập được như bình thường hay đã được “bỏ phiếu” bởi người viết. Nofollow đã được biết tới như một phương pháp để giúp ngăn chặn bình luận tự động ở blog, hay spam link. Nhưng hiện nay nó được biết tới như một cách nói cho các công cụ để giảm giá trị của liên kết được nói tới. Liên kết với thuộc tính “nofollow” được giải mã đôi chút khác biệt đối với các công cụ tìm kiếm khác nhau.
Theo: http://moz.com/


